A Simple Seldonian Algorithm
Remember that we are following the three steps of the Seldonian framework:
-
Define the goal for the designer of the algorithm. Our goal is to create an algorithm \(a\) that attempts to maximize an objective function \(f\) and ensures that the behavioral constraints are satisfied. That is, we are searching for an algorithm \(a\) that is an approximate solution to:
$$ \arg\max_{a \in \mathcal A}f(a)\\\text{s.t. }\forall i \in \{1,\dotsc,n\} \Pr(g_i(a(D)) \leq 0) \geq 1-\delta_i. $$In this example, the goal is to create a regression algorithm \(a\) that minimizes the negative MSE of the solution that \(a\) returns for the user's application. Because we do not know the value of \(f(a)\) for any \(a\) (since we do not know, for instance, to which datasets the user will apply the algorithm), we allow the user to provide a sample objective function \(\hat f:\Theta \times \mathcal D \to \mathbb R\) that acts as an estimate of the utility of any algorithm that returns the solution \(\theta\), when given input data \(D\). In our case, \(\hat f(\theta,D)=\frac{1}{n}\sum_{i=1}^n (\hat y(X_i,\theta)-Y_i)^2\).
-
Define the interface that the user will use. We will begin by using an interface that makes creating the Seldonian algorithm easier. Our initial interface will require the user to provide functions \(\hat g_i\), as described in the previous tutorial.
- Create the algorithm.
We will implement the following algorithm.
First, the data \(D\) is partitioned into two sets, \(D_1\) and \(D_2\). We call \(D_1\) the candidate data and \(D_2\) the safety data. Once the data has been partitioned, a method called Candidate Selection uses the candidate data to pick a single solution, \(\theta_c\), called the candidate solution, which the algorithm considers returning. The candidate solution is then passed to the Safety Test mechanism, which uses the safety data to test whether the candidate solution is safe to return. If so, it is returned, and if not the algorithm returns No Solution Found (NSF).
A diagram of this algorithm is provided below.
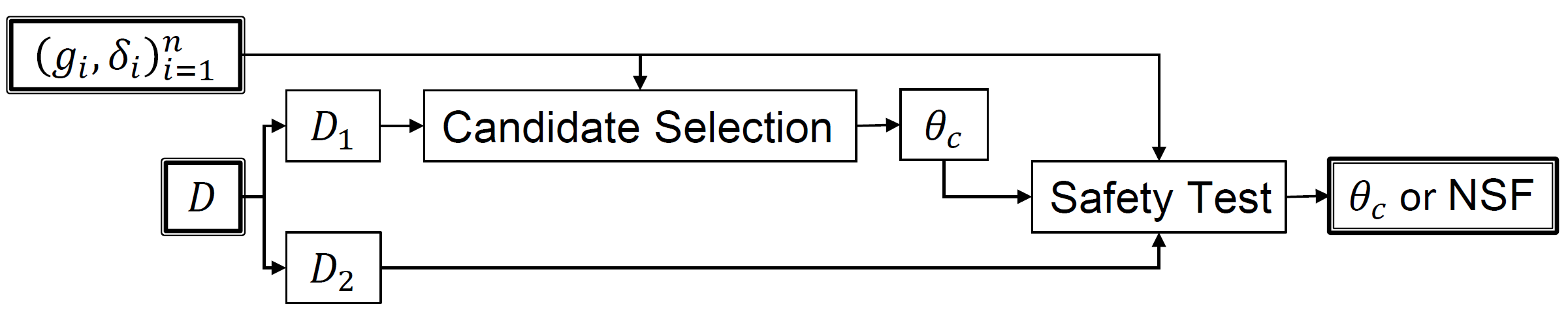
Figure S15 (supplemental materials) from P. S. Thomas, B. Castro da Silva, A. G. Barto, S. Giguere, Y. Brun, and E. Brunskill. Preventing undesirable behavior of intelligent machines. Science, 366:999–1004, 2019. Reprinted with permission from AAAS.