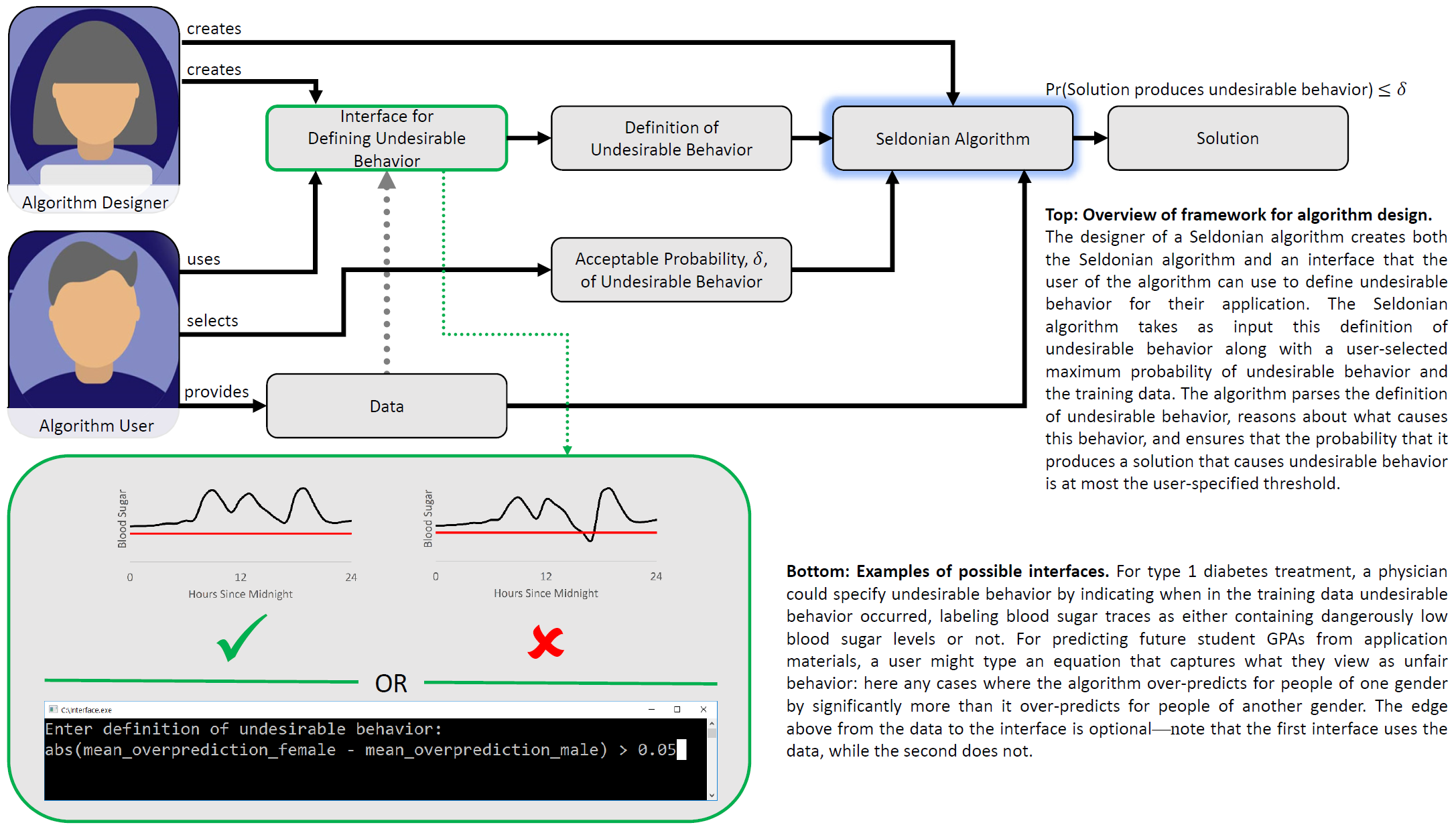
AI Safety
Intelligent machines using artificial intelligence (AI) and machine learning (ML) techniques are becoming increasingly common. They enable self-driving cars[1] and influence decisions including who should receive a loan,[2] who will get a job,[3] how long people will spend in prison,[4] and which treatments a patient will receive when in the intensive care unit.[5] Ensuring that these intelligent machines are well-behaved—that they do not, for example, harm humans or act in a racist or sexist way—is therefore not a hypothetical problem to be dealt with in science fiction movies or the distant future, but a pressing one that the research community has begun to address,[6] and which we tackle in our report recently published in Science.[7]
Today, researchers create ML algorithms that are applied by people across the sciences, businesses, and governments. We refer to these people who are applying ML algorithms to real problems as the users of the ML algorithms. Although these users may be experts in their own fields, they often are not experts in ML and statistics. It is therefore unreasonable to expect them to ensure that ML systems are well-behaved. So, when ML systems misbehave, we believe the question should be "how could we have designed ML algorithms that would have allowed the user to avoid this undesirable outcome?" not "what did the user do wrong when applying our ML algorithms?" The frequency of misbehaving ML algorithms[4, 8, 9, 10] is evidence that a few irresponsible users is not the root cause of the problem. Rather, misbehaving ML algorithms is a systemic problem beginning with the standard framework for designing ML algorithms, which fails to emphasize the importance of providing users with sufficient control over ML algorithms.
In our work, we study how we can ensure that ML algorithms are obedient. That is, how can we enable a person, who may not know how to program a computer, to tell an ML algorithm which behaviors are dangerous, racist, or otherwise undesirable? How can we then ensure that ML algorithms will respect commands to avoid these undesirable behaviors?
Seldonian Algorithms
We propose a new framework for designing ML algorithms. This new framework shifts the burden of ensuring that ML systems are well-behaved from the user of the algorithm to the designer of the algorithm, typically an ML researcher. Our framework has three steps, described in detail in our paper and its supplementary materials.[7] Algorithms designed using our framework are called Seldonian after the eponymous character in Asimov's Foundation series. Here, we highlight three of the key properties of our framework:
-
Interface: When using our framework, the designer of an ML algorithm must provide an interface that the user of the algorithm can use to specify the definition of undesirable behavior that is appropriate for their application. Although we do not place restrictions on how this interface can function, we encourage ML researchers to create interfaces that will be easy for non-experts to use.
For example, it would be unreasonable to expect the user (or anyone) to know which connections or weights in a large neural network controlling a robot would cause it to harm a human. So, the interface should not require users to have this knowledge. However, the user can likely recognize undesirable behavior—they can look at logs showing what happened in the past (or simulations of what could occur) and can label them as containing undesirable behavior or not. In our paper, we present a Seldonian reinforcement learning algorithm that uses an interface like this, which requires the user to be able to recognize undesirable behavior, but does not require the user to know what causes undesirable behavior.
As another example, we experimented with predicting student GPAs during the first three semesters at university based on their entrance exam scores. For this application, we used a different interface that allowed the user to write an equation that describes what they view as unfair behavior. Our algorithms then parse this equation and ensure that they behave fairly.
Designing even better interfaces is an important new research area. We are exicted by the possibilities of improved interfaces that could enable the user to define undesirable behavior via text, speech, a conversation, or by providing demonstrations of desirable behavior (researchers at UT Austin have recently shown that the latter may be feasible[11]). -
High-Probability Constraints: Seldonian algorithms guarantee with high-probability that they will not cause the undesirable behavior that the user specified via the interface. This is challenging because the ML researcher designing the algorithm will not know the user's definition of undesirable behavior when creating the ML algorithm. Hence, the ML algorithm must be particularly intelligent. It must have the ability to understand the user's definition of undesirable behavior, reason on its own about what would cause this undesirable behavior, and then take steps to ensure that it will avoid undesirable behavior.
The guarantees that Seldonian algorithms provide hold with high-probability, not certainty. This is because requiring the ML algorithm to have certainty would cause it to be paralyzed with indecision—unable to act because it cannot be absolutely certain that it will never cause harm. Without certainty that undesirable behavior will never occur, how can one apply ML algorithms responsibly to high-risk problems? Seldonian algorithms allow the user of the algorithm to specify a probability, and guarantee that the probability that they produce undesirable behavior will be no more than this user-selected probability. This enables users of Seldonian algorithms to specify the maximum probabiliy of undesirable behavior appropriately for the application at hand. -
No Solution Found: What if the user defines undesirable behavior in a way that it is impossible to avoid? For example, several common definitions of fairness cannot be satisfied simultaneously.[12] Alternatively, what if the user asks for a very-high probability guarantee but only provides the algorithm with a small amount of data? These issues arise as a consequence of giving the user the flexibility to define undesirable behavior and select the maximum probability of failure as they see fit. To handle these cases, Seldonian algorithms must have the ability to say No Solution Found (NSF) to indicate that they were unable to achieve what they were asked.
Example: GPA Prediction
Consider the problem of predicting student GPAs during the first three semesters at university based on their entrance exam scores. A system capable of providing accurate predictions could be used to filter student applications, much like automated systems for filtering resumes of job applicants.[13] To study this problem, we applied three standard ML algorithms to data from 43,303 students. The three standard algorithms use least squares linear regression (LR), an artificial neural network (ANN), and a random forest (RF). The plot below shows the behavior of these algorithms when predicting student GPAs:
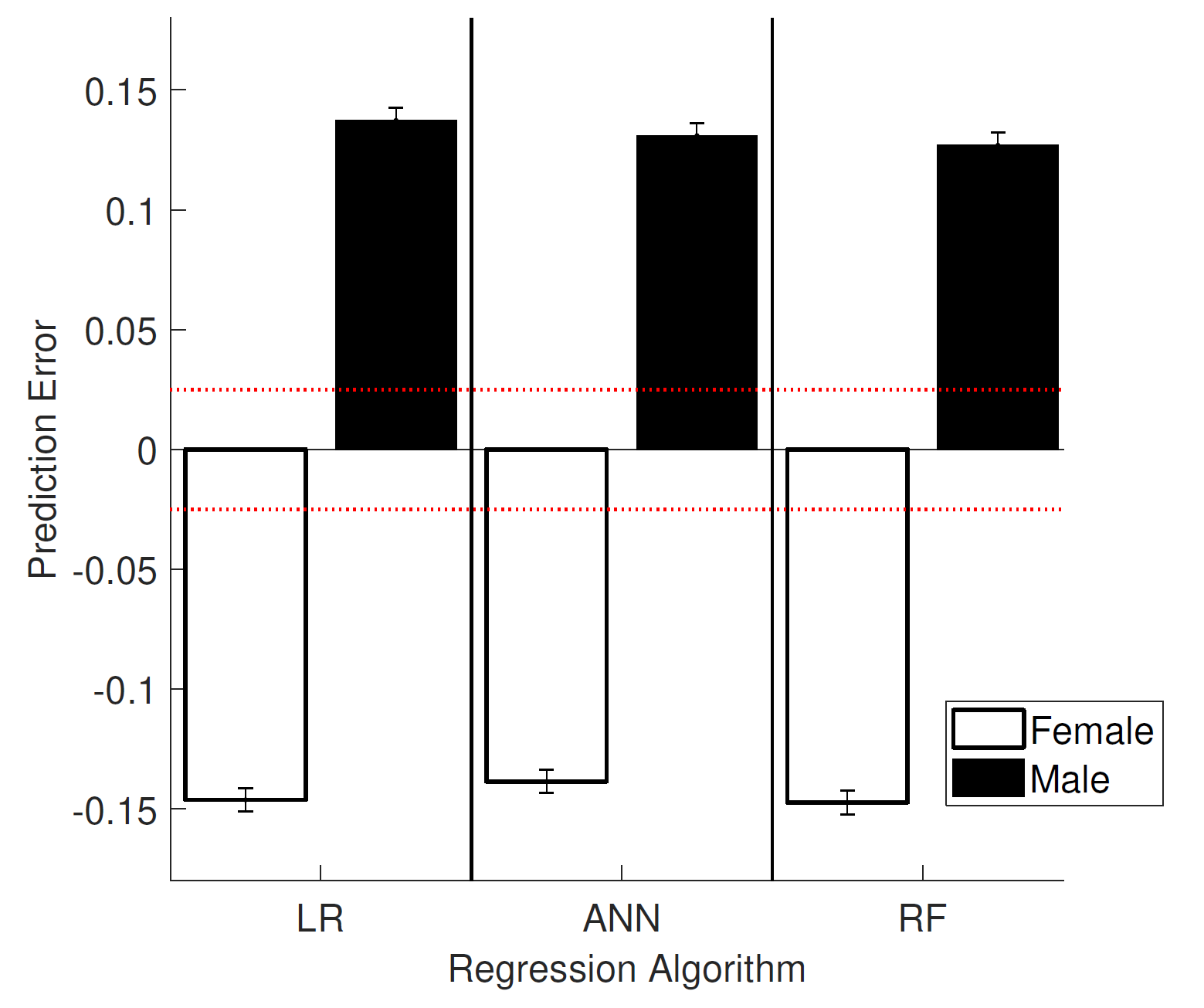
From P. S. Thomas, B. Castro da Silva, A. G. Barto, S. Giguere, Y. Brun, and E. Brunskill. Preventing undesirable behavior of intelligent machines. Science, 366:999–1004, 2019. Reprinted with permission from AAAS.
The height of each bar is the mean prediction error (how much each algorithm over-predicts, on average) for either male or female students. Since GPAs are on a 4.0 scale, this difference in mean prediction errors of approximately 0.3 GPA points corresponds to significant discrimination against female students. In the supplementary materials of our paper we describe the many reasons that this type of unfair behavior can occur. We conclude that there are many possible reasons, and that expecting the user of an ML algorithm to properly identify and remedy the cause of unfair behavior would be unreasonable.
By contrast, Seldonian algorithms can automatically identify and remedy the causes of unfair behavior in this example. In the following plot we include two variants of a Seldonian algorithm that we designed. This algorithm was tasked with ensuring that the difference between the mean prediction errors for male and female students was no more than \(\epsilon=0.05\), which they achieved succesfully (with \(1-\delta=0.95\), our algorithms never returned No Solution Found):
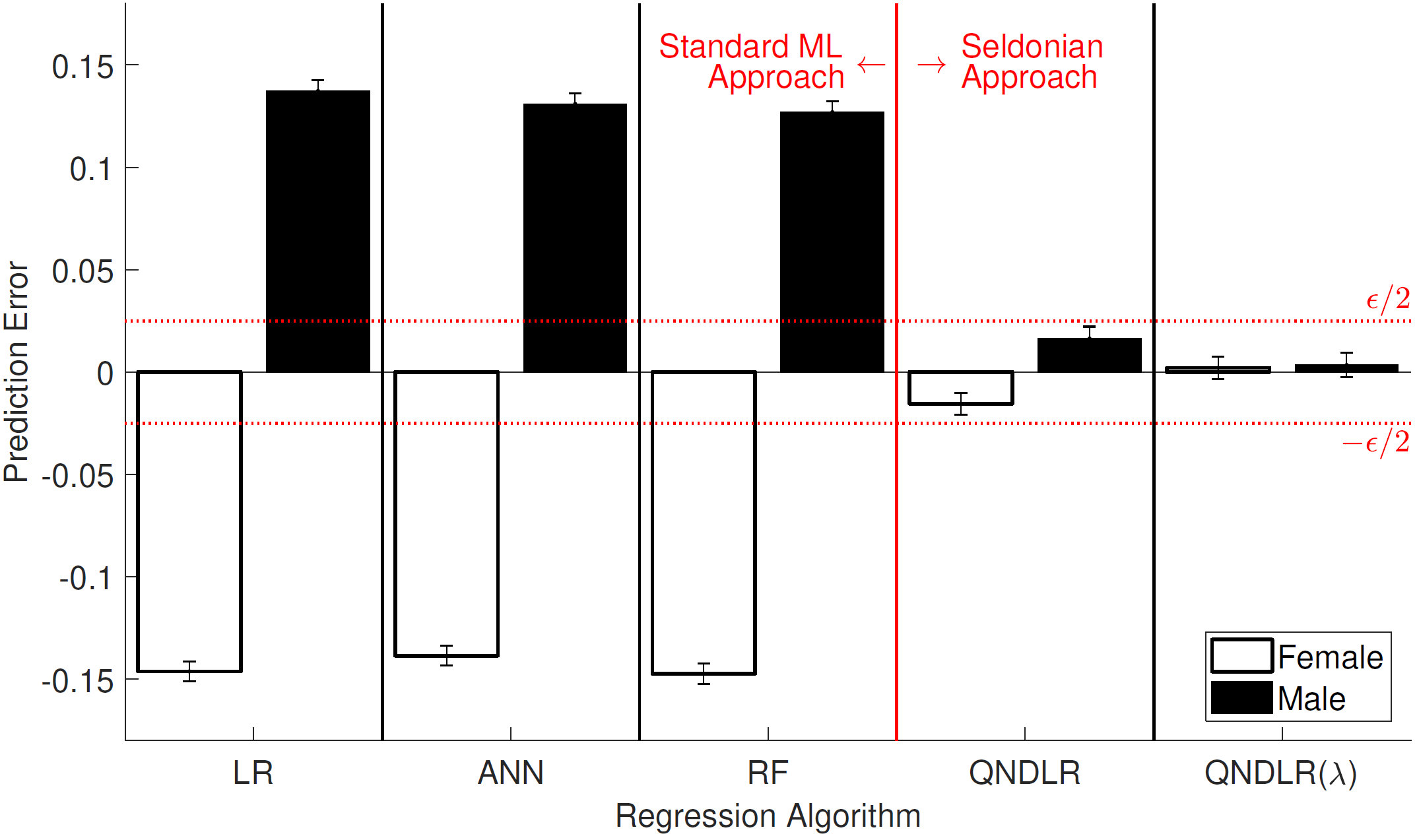
From P. S. Thomas, B. Castro da Silva, A. G. Barto, S. Giguere, Y. Brun, and E. Brunskill. Preventing undesirable behavior of intelligent machines. Science, 366:999–1004, 2019. Reprinted with permission from AAAS.
In ML fairness research, many different definitions of fairness have been proposed (this video describes 21). What if the user of the algorithm's definition of unfair behavior differs from the one that we used above? For example, what if the user wants to ensure that the mean predictions are similar for male and female applicants, not necessarily the mean prediction errors? That is, what if someone wants the algorithm to make the same prediction, on average, for men and women? This is where the interface becomes important.
To show that Seldonian algorithms with flexible interfaces can be developed, we created a Seldonian classification algorithm and used it to predict whether or not a student's GPA will be above 3.0. Unlike predicting the GPA directly, this yes/no type of decision is compatible with many of the previously mentioned 21 definitions of fairness. The Seldonian algorithm's interface allows the user of the algorithm to type an equation that characterizes unfair behavior. This equation can include several common variables, like the false positive rate (FP), false negative rate (FN), true positive rate (TP), true negative rate (TN), false positive rate given that the student is male (FP[male]), etc. Using an interface of this type, the user might enter:
| FN[male] - FN[female] | \(\leq\) 0.1
to indicate that the difference between the false negative rates for male and female applicants should be at most 0.1, or
max(FN[male]/FN[female],FN[female]/FN[male]) < 1.1
to indicate that the ratio of false negative rates should be within ten percent of each other. Rather than make up our own definitions of fairness, in our paper we applied a Seldonian algorithm with an interface of this type to enforce five common definitions of fairness in the ML literature: disparate impact, demographic parity, equal opportunity, equalized odds, and predictive equality. We compared the performance of our algorithms to two state-of-the-art fairness-aware ML algorithms.
Our algorithm was the only one to have a general interface that puts the power to define undesirable (unfair) behavior in the user's hands. As a result, even though the other algorithms were sometimes successful at avoiding unfair behavior, all non-Seldonian algorithms produced wildly unfair behavior when tasked with enforcing at least one of these five definitions of fairness. Additionally, our algorithm was the only one to provide high-probability guarantees that it will not produce unfair behavior. As result, it was the only one to succesfully ensure with high probability that it would not produce unfair behavior. These results are summarized in Fig. 3 of our paper.[7]
Also, in work that we presented at the conference Advances in Neural Information Processing Systems (NeurIPS) in December 2019, we showed how similar algorithms (a special type of ML algorithm called a contextual bandit algorithm) can avoid unfair behavior when predicting whether someone will repay a loan, predicting whether someone will commit a crime in the future, and when automatically improving an online tutorial (an intelligent tutoring system), all using real data.[14]
Example: Diabetes Treatment
Seldonian algorithms are for more than just ensuring fairness: they are for avoiding all types of undesirable behaviors. To show this, and to provide an example of an interface that does not require knowledge about statistics, consider the problem of automatically improving a controller within an insulin pump—a bolus insulin calculator. Bolus insulin calculators determine how much insulin should be injected into the blood of a person with type 1 diabetes before they eat a meal. If too much is injected, blood sugar levels can become dangerously low—a condition called hypoglycemia. If too little is injected, then the person's blood sugar levels can remain too high—a condition called hyperglycemia. The ideal amount to inject depends on the individual, and so there has been recent interest in creating bolus calculators that can adapt to the metabolism of an individual. Reinforcement learning algorithms are a type of ML algorithm that are well-suited to this type of problem.[13]
For this application, a medical researcher using a reinforcement learning algorithm might know that they want to enforce a safety constraint that ensures that the frequency of hypoglycemia is not increased, since hypoglycemia is generally considered to be more severe than hyperglycemia. However, the user may not know all of the intricate details of an individual's metabolism, and so they cannot know which settings of a bolus calculator would increase the frequency of hypoglycemia for the individual, and which would not.
We therefore desire an interface that only requires the user to recognize undesirable behavior, not an interface that requires the user to know what parameter settings would cause undesirable behavior. We provide one example of such an interface: the user can label data to indicate whether or not undesirable behavior occurred. In this case, the medical researcher could look at traces of blood sugar levels, and indicate which ones contain undesirable behavior—which contain blood sugar levels below the threshold for hypoglycemia. Below, the left image would not be labeled as containing undesirable behavior, while the right would.
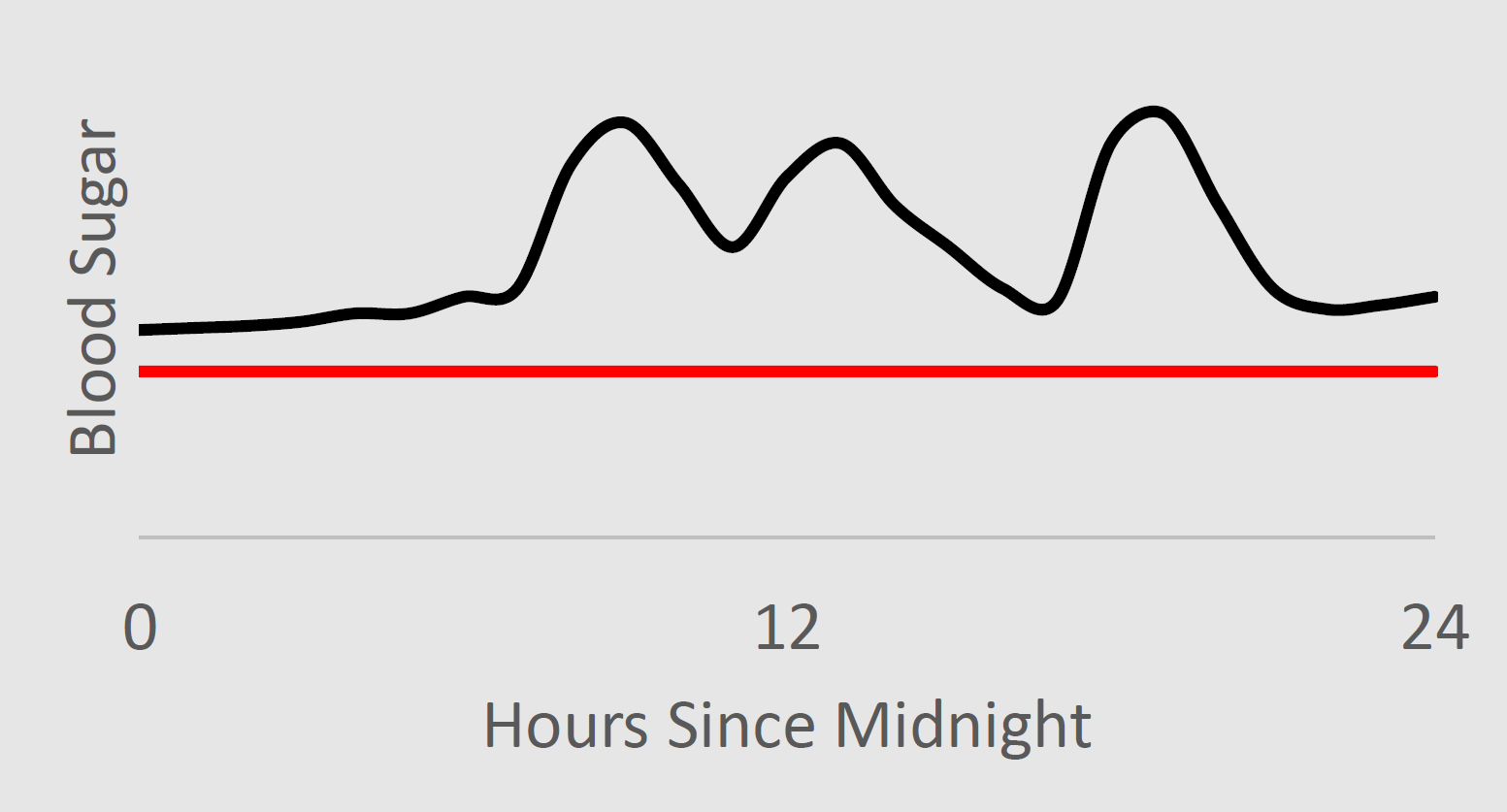
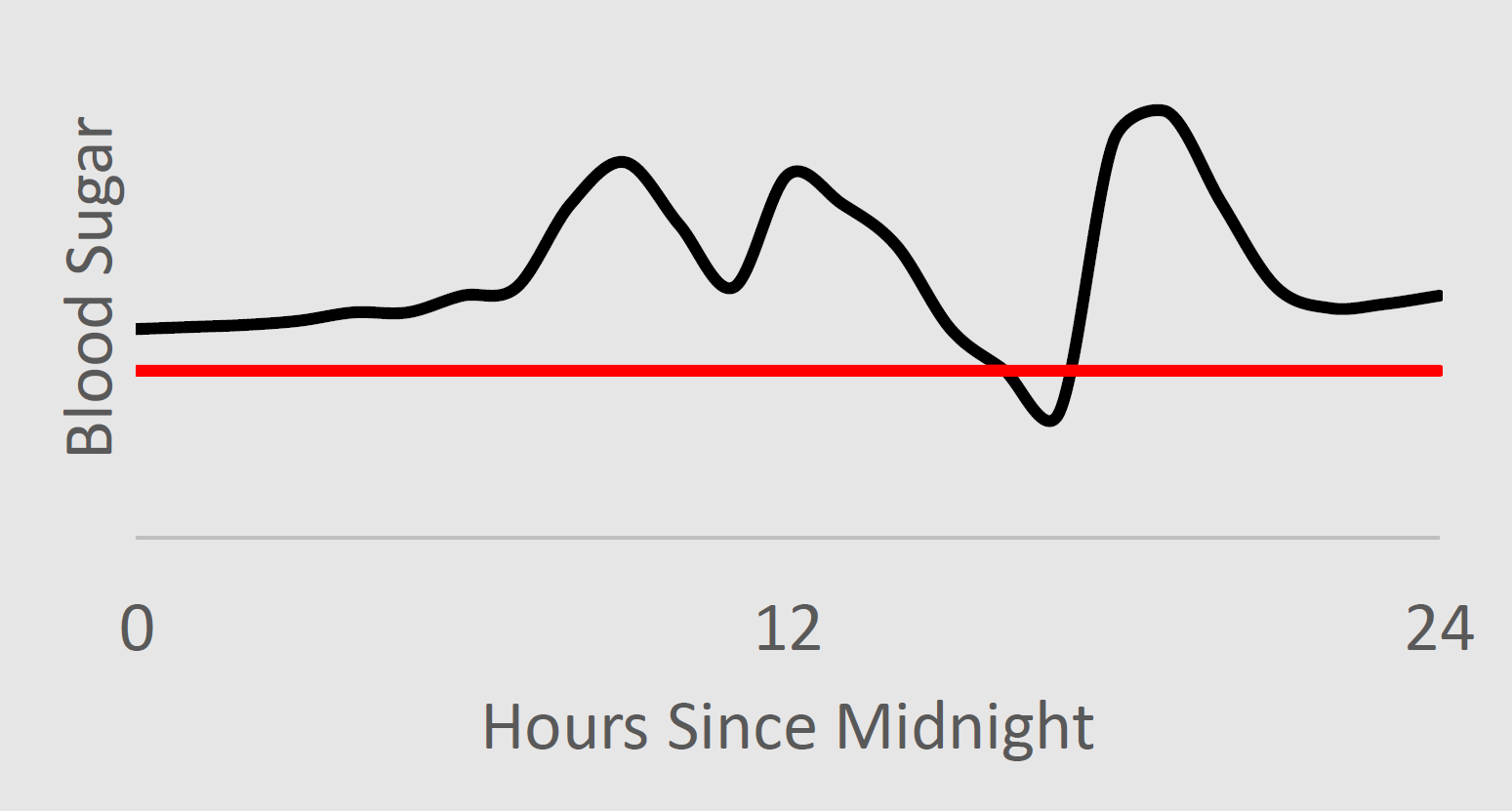
Given these labels indicating when in the past undesirable outcomes occurred, our algorithm guarantees with high probability that it will not change the way it makes decisions in a way that increases the frequency of undesirable outcomes—here this means that it guarantees with high probability that it will not change the controller within the insulin pump in a way that increases the frequency of hypoglycemia.
Current State of the Art
The Seldonian algorithms that we have created so far are surprisingly simple. Our goal is not to promote the use of these specific algorithms, but to encourage machine learning researchers to create new and improved Seldonian algorithms—algorithms that can return solutions using less data and algorithms with improved interfaces that make it particularly easy for the user to control the behavior of the algorithm. In the tutorials section of this website, we will show you how to quickly create a state-of-the-art Seldonian algorithm. We hope that you will see how we created our algorithms and will recognize "I can do this better," resulting in advances in the new field of creating Seldonian algorithms, or "I can use these algorithms," resulting in the responsible application of machine learning.